在人工智能和机器学习快速发展的今天,企业对于AI模型的管理和部署提出了更高的要求。模型控制平台(Model Control Platform, MCP)作为一种新兴的架构模式,能够有效地管理多种AI模型,提供统一的访问接口,并实施企业级的安全策略。本文将详细介绍如何使用Spring Boot 2.2构建一个简单而功能完备的MCP Server。
MCP架构概述
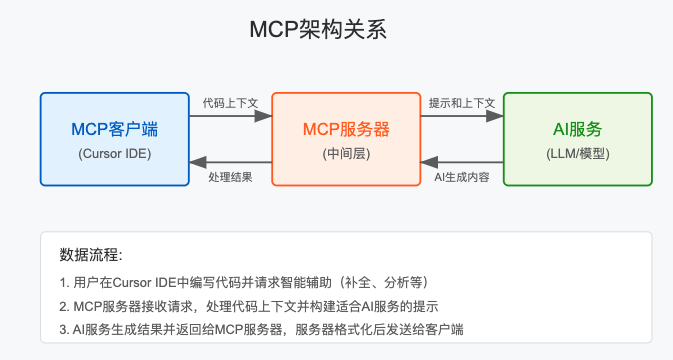
在深入代码实现之前,让我们先了解MCP的整体架构以及各组件的作用:
- MCP Client:企业内部应用和集成点,如Cursor编辑器
- MCP Gateway:实施企业安全策略的网关
- MCP Router:管理对多个模型供应商的访问
- MCP Server:提供模型服务,可能是混合模式(自托管和第三方)
- MCP Host:私有云或混合云环境
在这个架构中,MCP Server扮演着关键角色,它负责实际的模型加载、推理计算以及资源管理,是整个系统的计算核心。
准备工作
开始之前,确保您的开发环境满足以下要求:
- JDK 8或更高版本
- Maven 3.6+或Gradle 6.0+
- IDE(推荐使用IntelliJ IDEA或Spring Tool Suite)
- 基础的Spring Boot知识
项目初始化
首先,我们需要创建一个基础的Spring Boot项目。可以使用Spring Initializr(https://start.spring.io/)或直接在IDE中创建。
项目依赖
我们的MCP Server需要以下核心依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
项目结构
推荐的项目结构如下:
src/main/java/com/example/mcpserver/
- McpServerApplication.java # 应用入口
- config/ # 配置类
- controller/ # REST API控制器
- service/ # 业务逻辑服务
- model/ # 数据模型和DTO
- exception/ # 自定义异常处理
- util/ # 工具类
核心组件实现
1. 数据模型设计
首先,让我们定义表示AI模型的基础类:
package com.example.mcpserver.model;
import lombok.Data;
import java.util.Map;
@Data
public class AIModel {
private String id;
private String name;
private String version;
private String path;
private boolean loaded;
private Map<String, Object> metadata;
}
接下来,我们需要为推理请求和响应创建数据传输对象(DTO):
package com.example.mcpserver.model.dto;
import lombok.Data;
import java.util.Map;
@Data
public class InferenceRequest {
private String modelId;
private String prompt;
private Map<String, Object> parameters;
}
@Data
public class InferenceResponse {
private String modelId;
private String result;
private long latency;
private Map<String, Object> metadata;
}
2. 服务层实现
我们首先定义模型服务的接口:
package com.example.mcpserver.service;
import com.example.mcpserver.model.AIModel;
import com.example.mcpserver.model.dto.InferenceRequest;
import com.example.mcpserver.model.dto.InferenceResponse;
import java.util.List;
public interface ModelService {
List<AIModel> listModels();
AIModel getModel(String modelId);
boolean loadModel(String modelId);
boolean unloadModel(String modelId);
InferenceResponse infer(InferenceRequest request);
}
然后,我们实现这个接口:
package com.example.mcpserver.service.impl;
import com.example.mcpserver.model.AIModel;
import com.example.mcpserver.model.dto.InferenceRequest;
import com.example.mcpserver.model.dto.InferenceResponse;
import com.example.mcpserver.service.ModelService;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
@Service
public class ModelServiceImpl implements ModelService {
@Value("${mcp.models.base-path}")
private String basePath;
private final Map<String, AIModel> models = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
// 初始化模型列表,实际应用中可能从配置或数据库加载
AIModel demoModel = new AIModel();
demoModel.setId("gpt2");
demoModel.setName("GPT-2");
demoModel.setVersion("1.0");
demoModel.setPath(basePath + "/gpt2");
demoModel.setLoaded(false);
demoModel.setMetadata(Map.of("type", "text-generation", "parameters", 124000000));
models.put(demoModel.getId(), demoModel);
}
@Override
public List<AIModel> listModels() {
return new ArrayList<>(models.values());
}
@Override
public AIModel getModel(String modelId) {
return models.get(modelId);
}
@Override
public boolean loadModel(String modelId) {
AIModel model = models.get(modelId);
if (model != null && !model.isLoaded()) {
// 实际加载模型的代码,这里简化处理
model.setLoaded(true);
return true;
}
return false;
}
@Override
public boolean unloadModel(String modelId) {
AIModel model = models.get(modelId);
if (model != null && model.isLoaded()) {
// 实际卸载模型的代码,这里简化处理
model.setLoaded(false);
return true;
}
return false;
}
@Override
public InferenceResponse infer(InferenceRequest request) {
AIModel model = models.get(request.getModelId());
if (model == null || !model.isLoaded()) {
throw new RuntimeException("Model not available");
}
long startTime = System.currentTimeMillis();
// 实际的模型推理代码,这里用示例实现
String result = "This is a sample response from " + model.getName();
long latency = System.currentTimeMillis() - startTime;
InferenceResponse response = new InferenceResponse();
response.setModelId(model.getId());
response.setResult(result);
response.setLatency(latency);
response.setMetadata(Map.of("tokenCount", 10));
return response;
}
}
3. REST API控制器
接下来,我们创建REST API控制器,暴露服务接口:
package com.example.mcpserver.controller;
import com.example.mcpserver.model.AIModel;
import com.example.mcpserver.model.dto.InferenceRequest;
import com.example.mcpserver.model.dto.InferenceResponse;
import com.example.mcpserver.service.ModelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/api/v1")
public class ModelController {
@Autowired
private ModelService modelService;
@GetMapping("/models")
public ResponseEntity<List<AIModel>> listModels() {
return ResponseEntity.ok(modelService.listModels());
}
@GetMapping("/models/{modelId}")
public ResponseEntity<AIModel> getModel(@PathVariable String modelId) {
AIModel model = modelService.getModel(modelId);
if (model == null) {
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(model);
}
@PostMapping("/models/{modelId}/load")
public ResponseEntity<Map<String, Boolean>> loadModel(@PathVariable String modelId) {
boolean success = modelService.loadModel(modelId);
return ResponseEntity.ok(Map.of("success", success));
}
@PostMapping("/models/{modelId}/unload")
public ResponseEntity<Map<String, Boolean>> unloadModel(@PathVariable String modelId) {
boolean success = modelService.unloadModel(modelId);
return ResponseEntity.ok(Map.of("success", success));
}
@PostMapping("/infer")
public ResponseEntity<InferenceResponse> infer(@RequestBody InferenceRequest request) {
InferenceResponse response = modelService.infer(request);
return ResponseEntity.ok(response);
}
@GetMapping("/health")
public ResponseEntity<Map<String, String>> health() {
return ResponseEntity.ok(Map.of("status", "OK"));
}
}
4. 安全配置
最后,我们添加基本的安全配置:
package com.example.mcpserver.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable()
.authorizeRequests()
.antMatchers("/api/v1/health").permitAll() // 健康检查端点不需要认证
.anyRequest().authenticated()
.and()
.httpBasic() // 简单实现,生产环境应使用JWT或OAuth2
.and()
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS);
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}
5. 配置属性
为了完成我们的应用,我们需要在application.properties中定义一些属性:
server.port=8080
spring.application.name=mcp-server
# 模型配置
mcp.models.base-path=/opt/mcp/models
mcp.models.default=gpt2
# 安全配置
mcp.security.jwt.secret=mcpSecretKey
mcp.security.jwt.expiration=86400000
# 资源限制
mcp.resources.max-concurrent-requests=10
mcp.resources.request-timeout=30000
实际案例:集成外部模型
到目前为止,我们已经搭建了一个基础的MCP Server框架。下面我们通过一个实际案例,展示如何集成外部模型库。
使用DJL (Deep Java Library)集成HuggingFace模型
首先,添加DJL依赖:
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>0.19.0</version>
</dependency>
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.19.0</version>
</dependency>
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>0.19.0</version>
</dependency>
然后,创建一个专门的模型推理服务:
package com.example.mcpserver.service.impl;
import ai.djl.Device;
import ai.djl.inference.Predictor;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.training.util.ProgressBar;
import org.springframework.stereotype.Service;
import java.nio.file.Paths;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Service
public class DJLModelService {
private final Map<String, ZooModel<?>> loadedModels = new ConcurrentHashMap<>();
public boolean loadHuggingFaceModel(String modelId, String modelPath) {
try {
Criteria<?> criteria = Criteria.builder()
.setTypes(String.class, String.class)
.optModelPath(Paths.get(modelPath))
.optDevice(Device.cpu())
.optProgress(new ProgressBar())
.build();
ZooModel<?> model = criteria.loadModel();
loadedModels.put(modelId, model);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
public String generateText(String modelId, String prompt, Map<String, Object> parameters) {
ZooModel<?> model = loadedModels.get(modelId);
if (model == null) {
throw new RuntimeException("Model not loaded: " + modelId);
}
try (Predictor<String, String> predictor = model.newPredictor()) {
return predictor.predict(prompt);
} catch (Exception e) {
throw new RuntimeException("Inference failed", e);
}
}
public void unloadModel(String modelId) {
ZooModel<?> model = loadedModels.remove(modelId);
if (model != null) {
model.close();
}
}
}
接下来,修改我们的ModelServiceImpl类来集成这个DJL服务:
@Service
public class ModelServiceImpl implements ModelService {
@Autowired
private DJLModelService djlModelService;
// 其他代码保持不变
@Override
public boolean loadModel(String modelId) {
AIModel model = models.get(modelId);
if (model != null && !model.isLoaded()) {
boolean success = djlModelService.loadHuggingFaceModel(modelId, model.getPath());
if (success) {
model.setLoaded(true);
return true;
}
}
return false;
}
@Override
public boolean unloadModel(String modelId) {
AIModel model = models.get(modelId);
if (model != null && model.isLoaded()) {
djlModelService.unloadModel(modelId);
model.setLoaded(false);
return true;
}
return false;
}
@Override
public InferenceResponse infer(InferenceRequest request) {
AIModel model = models.get(request.getModelId());
if (model == null || !model.isLoaded()) {
throw new RuntimeException("Model not available");
}
long startTime = System.currentTimeMillis();
String result = djlModelService.generateText(
request.getModelId(),
request.getPrompt(),
request.getParameters()
);
long latency = System.currentTimeMillis() - startTime;
InferenceResponse response = new InferenceResponse();
response.setModelId(model.getId());
response.setResult(result);
response.setLatency(latency);
response.setMetadata(Map.of("tokenCount", result.split("\\s+").length));
return response;
}
}
高级功能拓展
到目前为止,我们已经构建了一个功能基本完备的MCP Server。在实际生产环境中,您可能需要考虑以下高级功能:
1. 负载均衡和并发控制
对于高请求量的场景,我们需要增加负载均衡和并发控制:
@Configuration
public class AsyncConfig {
@Value("${mcp.resources.max-concurrent-requests}")
private int maxConcurrentRequests;
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(maxConcurrentRequests / 2);
executor.setMaxPoolSize(maxConcurrentRequests);
executor.setQueueCapacity(500);
executor.setThreadNamePrefix("mcp-task-");
executor.initialize();
return executor;
}
}
然后在服务层中使用异步调用:
@Async
public CompletableFuture<InferenceResponse> inferAsync(InferenceRequest request) {
return CompletableFuture.completedFuture(infer(request));
}
2. 模型缓存和内存管理
对于大型模型,内存管理至关重要:
@Service
public class ModelCacheService {
@Value("${mcp.cache.max-models}")
private int maxModelsInMemory;
private final Map<String, Long> lastUsedTime = new ConcurrentHashMap<>();
public void trackModelUsage(String modelId) {
lastUsedTime.put(modelId, System.currentTimeMillis());
}
public String findModelToEvict() {
if (lastUsedTime.size() <= maxModelsInMemory) {
return null;
}
return lastUsedTime.entrySet().stream()
.min(Map.Entry.comparingByValue())
.map(Map.Entry::getKey)
.orElse(null);
}
}
3. 监控和指标
使用Spring Boot Actuator增加监控指标:
@Configuration
public class MetricsConfig {
@Bean
MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags("application", "mcp-server");
}
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}
}
在服务方法上添加指标注解:
@Timed(value = "model.inference", description = "Time taken for model inference")
public InferenceResponse infer(InferenceRequest request) {
// 现有代码
}
部署和扩展
Docker化部署
为了简化部署过程,我们可以创建一个Dockerfile:
FROM openjdk:11-jre-slim
WORKDIR /app
COPY target/mcp-server-0.0.1-SNAPSHOT.jar app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]
Kubernetes部署
对于更复杂的部署场景,可以使用Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-server
spec:
replicas: 3
selector:
matchLabels:
app: mcp-server
template:
metadata:
labels:
app: mcp-server
spec:
containers:
- name: mcp-server
image: mcp-server:latest
ports:
- containerPort: 8080
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "1"
memory: "2Gi"
env:
- name: SPRING_PROFILES_ACTIVE
value: "prod"
最佳实践总结
在构建MCP Server时,以下是一些值得注意的最佳实践:
- 模块化设计:将不同功能封装到独立的服务和控制器中
- 资源管理:注意模型的内存消耗,实现适当的缓存和释放机制
- 异常处理:使用全局异常处理器提供统一的错误响应
- 安全性:实施适当的认证和授权机制
- 可观察性:集成监控和日志记录功能
- 性能优化:使用异步处理和并发控制处理高负载
通过Spring Boot 2.2,我们可以快速构建一个功能完备的MCP Server,为企业提供统一的模型管理和推理服务。本文介绍的架构和实现可以作为基础,根据具体业务需求进行扩展和定制。
在实际开发中,您可能需要根据所使用的具体模型库和框架进行调整,但核心架构和接口设计原则是通用的。随着企业AI应用的不断发展,MCP作为一种架构模式将发挥越来越重要的作用。
参考资源